-
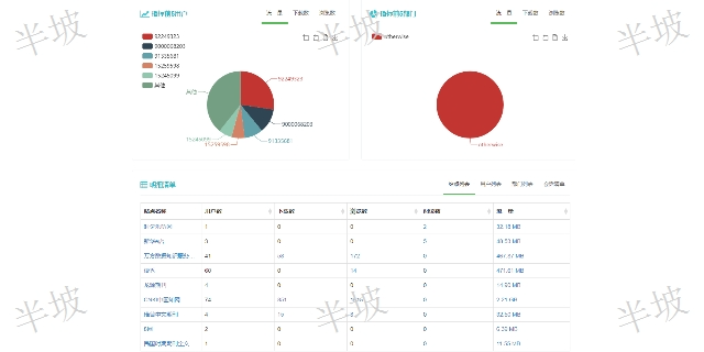 安徽互聯網文獻知識發現
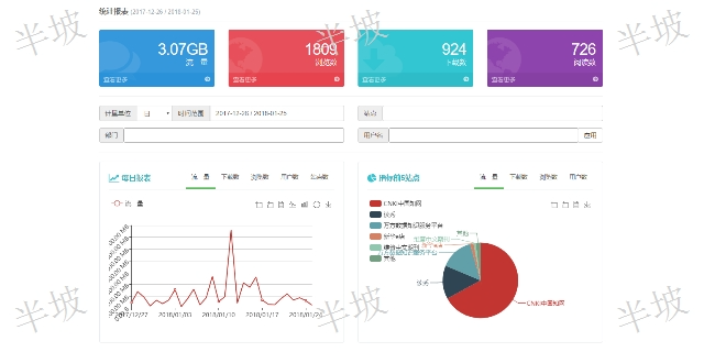
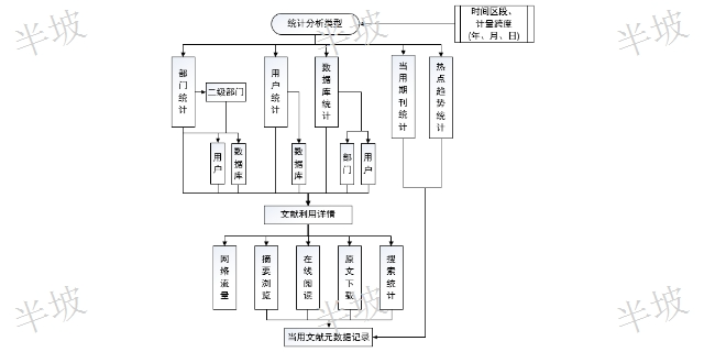
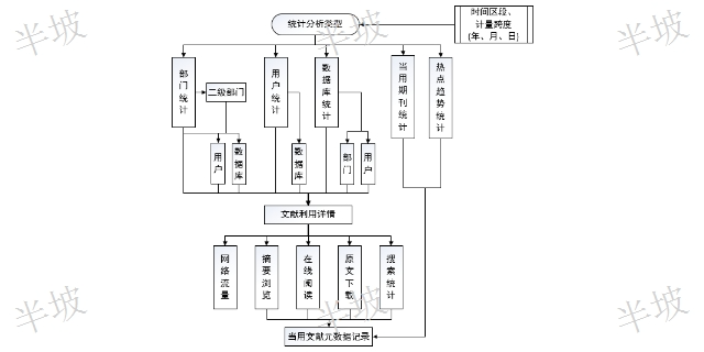
安徽互聯網文獻知識發現基于中樞網關模式的文獻利用統計將能夠提供針對圖書館所有文獻數據庫的、針對各個部門的、針對單個期刊品種的、針對單個讀者等等,以每篇閱讀文獻為基礎單位的文獻利用統計分析。能夠真實反映讀者和文獻數據庫利用情況,為圖書館讀者服務工作和為圖書館資源采購決策(包括試用數據庫)提供精細的科學依據。統計分析模塊中主要分為數據庫統計,用戶統計,部門統計。其中每種統計,都會對其流量,瀏覽數,下載數,閱讀數進行詳細統計。并且每種統計支持年月,日等相關條件限定。選擇對應的數據條件可以是單個條件,組合條件。例如:我們可以選擇一個具體的數據庫,,讀者,部門進行統計。也可以選擇對應部門下這個站點的使用情況,以及當前...
-
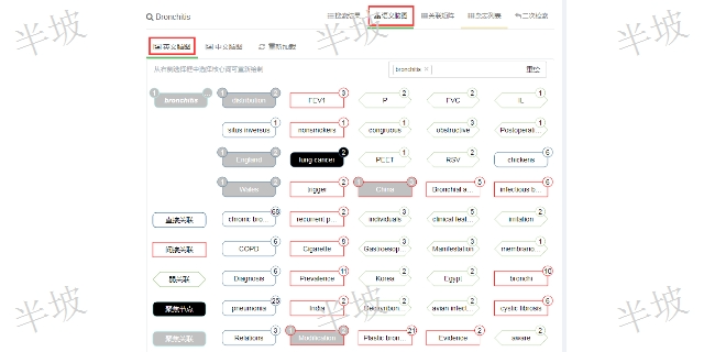 江蘇文獻知識發現平臺
江蘇文獻知識發現平臺隱性知識鏈發現:語義腦圖中,給定重心節點(搜索詞)A,任意興趣節點C(黑色背景);當A和C本身并沒有直接關聯的前提下,如果存在A-B語義直接關聯,并且B-C語義直接關聯,這類的概念節點B(具有藍色右下角標的節點),正是讀者在文獻閱讀過程中試圖去發現的A和C之間潛在的知識銜接節點。右下數字角標所標識鏈接的具體文獻,表示在其中的一篇文獻中,或在不同的兩篇文獻中,讀者可以找到這種隱性知識鏈的相關文獻內容。多維度發散思維:讀者可以選定語義腦圖中的任意概念詞(雙擊),則由此作為新的重心節點,系統將在搜索結果中重新提取與新的重心概念密切相關的概念語詞,重構一幅全新的語義關聯矩陣。任意一個概念語詞就...
-
 品牌文獻知識發現優勢
品牌文獻知識發現優勢語義關聯矩陣:首先,語義腦圖從當前所截獲的文獻中提取若干概念性語詞。例如讀者搜索“硫化氫”,系統會從當前搜索結果文獻的文本中實時提煉出脫硫劑、地下水、氣相色譜法、缺血、自噬、氨氮、污水處理廠等若干文本語詞。之后,語義腦圖以一個5列12行的關聯矩陣來表達概念語詞之間的語義關系:將讀者搜索詞排列在矩陣的左側一列作為起始中心節點,后續右側各列選詞由左鄰側列的概念語詞關聯推導產生,同一列內概念語詞按語義權重降序排列。然后,各個概念語詞依據和中心節點(搜索詞)的語義關聯度,在語義腦圖中表現為:中心節點(搜索詞),直接關聯節點(紅色邊框)、間接關聯節點(長方型邊框)、弱關聯節點(菱形邊框)等三個層...
-
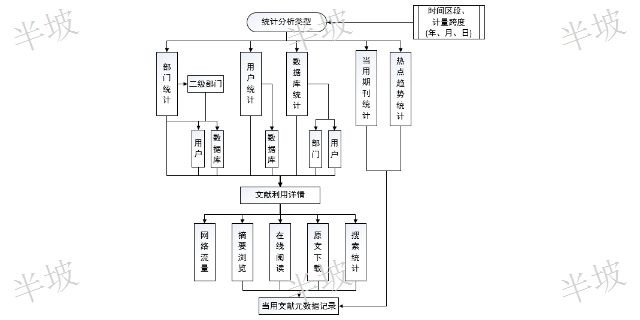
數字圖書館文獻知識發現簡介
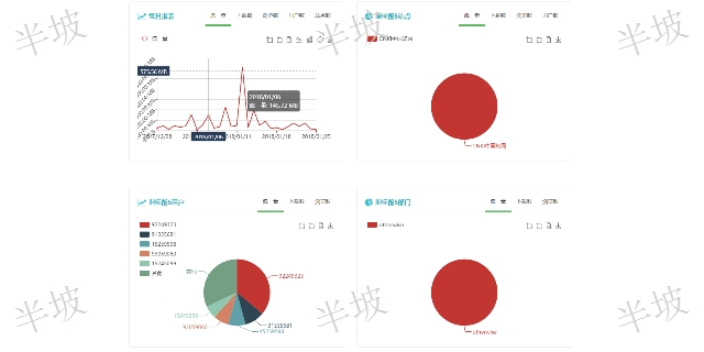
文獻數據庫列表明細:當前數據源檢索下的站點明細(如:數據源為一個數據庫,則在站點明細中只出現該數據可。) 在站點明細中可以,可以查看各個具體文獻數據庫的瀏覽,閱讀,下載,以及流量情況,支持對應排序。用戶列表明細,可以查看用戶具體的訪問情況,例如:當前選擇的數據源為CNKI這個數據庫。則在用戶列表中為所有用戶訪問CNKI的明細,包含,閱讀,下載,瀏覽,站點數以及流量。如選擇統計數據源為部門,則用戶站點數就為該用戶一共訪問的數據庫個數。 ?查詢文獻知識需要付費嗎?數字圖書館文獻知識發現簡介 作者是誰?他們還出版了什么?這篇論文是他們曾經研究內容的工作延伸嗎?文章的目的是什么?你認...
-
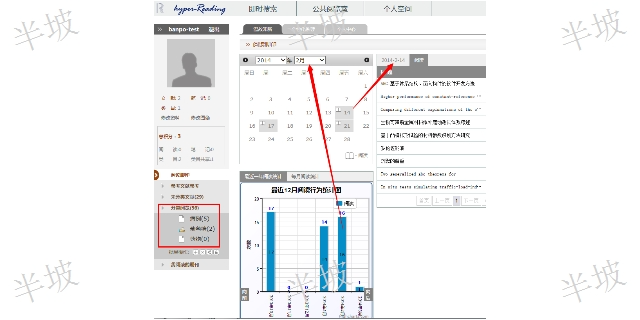 上海文獻知識發現咨詢熱線
上海文獻知識發現咨詢熱線自20世紀90年代以來,因特網延伸至全球各個角落,并深刻地改變了人們的工作、生活、學習方式。社會知識與文獻的生產傳播因此出現了新的特點,對文獻信息存取的認知也被賦予了新的意義,所有這些共同構成了一個全新的信息環境。現代的計算機網絡技術,打破了地域和機構界限,超越了時間和空間的約束,使異地之間文獻信息的快速交流、利用成為現實,比較大限度地為人們提供了一個文獻獲取的“自由空間”。 但是,信息時代的來臨,任何一個圖書館都無法*靠本館館藏來滿足讀者對所有文獻資源的需求,通過文獻傳遞以實現資源共享而更好地滿足讀者的需求是大勢所趨。文獻傳遞是圖書館在數字環境下為了滿足用戶對本館未收藏文獻的需求而開展的服務...
-
 提供文獻知識發現標志
提供文獻知識發現標志文獻數據庫簡介一、定義及分類:文獻數據庫,是指計算機可讀的、有組織的相關文獻信息的**。按照國別分:可分為外文文獻數據庫及中文文獻數據庫按照信息類別可分為:期刊論文數據庫、**數據庫、會議論文數據庫、學位論文數據庫……;按照學科領域分類,例如生命科學領域有PubMed數據庫,工程技術領域有EI數據庫,化學領域的SciFinder,Reaxys,F1000,NANO數據庫;按照信息類型可分為:全文數據庫及文摘數據庫。1)中文全文數據庫舉例:2)英文全文數據庫舉例:3)文摘數據庫二.文摘數據庫與全文數據庫的比較二者主要區別在于用戶在全文數據庫中可以直接下載文獻,而文摘型數據庫只提供了全文鏈接,無法...
-
江西互聯網文獻知識發現
自20世紀90年代以來,因特網延伸至全球各個角落,并深刻地改變了人們的工作、生活、學習方式。社會知識與文獻的生產傳播因此出現了新的特點,對文獻信息存取的認知也被賦予了新的意義,所有這些共同構成了一個全新的信息環境。現代的計算機網絡技術,打破了地域和機構界限,超越了時間和空間的約束,使異地之間文獻信息的快速交流、利用成為現實,比較大限度地為人們提供了一個文獻獲取的“自由空間”。 但是,信息時代的來臨,任何一個圖書館都無法*靠本館館藏來滿足讀者對所有文獻資源的需求,通過文獻傳遞以實現資源共享而更好地滿足讀者的需求是大勢所趨。文獻傳遞是圖書館在數字環境下為了滿足用戶對本館未收藏文獻的需求而開展的服務...
-
江蘇文獻知識發現成本
左側的語義腦圖中任意節點可以在右側文獻詳情界面顯示其相關文獻。右側相關文獻界面則進一步揭示了當前文獻中所有的概念語詞(紅色下劃線)。選擇其中的任意詞(鼠標定位),可以查看該概念詞所有的相關文獻,并且以該概念詞為中心節點,可以在左側語義腦圖子窗口,重構一幅全新的語義腦圖(發明專項權利)。紅色下劃線標注了一篇文獻中的所有細分概念《嵌入式知識鏈分析》無縫嵌入原始文獻數據庫,將傳統文獻搜索引擎一維的文獻顯示模式提升為二維的概念語詞級別的關聯矩陣顯示模式。其基于實時搜索結果的知識層面的語義概念專指、聚類、收斂、發散、顯性、隱性及其多維度的關聯揭示等功能特色,在尤為強調知識發現、知識創新的當日,將...
-
互聯網文獻知識發現聯系人
文獻數據庫簡介一、定義及分類:文獻數據庫,是指計算機可讀的、有組織的相關文獻信息的**。按照國別分:可分為外文文獻數據庫及中文文獻數據庫按照信息類別可分為:期刊論文數據庫、**數據庫、會議論文數據庫、學位論文數據庫……;按照學科領域分類,例如生命科學領域有PubMed數據庫,工程技術領域有EI數據庫,化學領域的SciFinder,Reaxys,F1000,NANO數據庫;按照信息類型可分為:全文數據庫及文摘數據庫。1)中文全文數據庫舉例:2)英文全文數據庫舉例:3)文摘數據庫二.文摘數據庫與全文數據庫的比較二者主要區別在于用戶在全文數據庫中可以直接下載文獻,而文摘型數據庫只提供了全文鏈接,無法...
-
 福建文獻知識發現大概價格多少
福建文獻知識發現大概價格多少一站式學術搜索結果界面:搜索結果文獻詳情包含了文獻標題,類型,作者,年卷,期刊來源以及文獻鏈接。在搜索結果文獻詳情部分,有“下一頁”按鈕,讀者可以持續點擊查看該文獻數據庫的后續命中文獻。在搜索結果文獻詳情部分,可以選中文獻,比較后以批量形式按指定格式導出結果文獻。l界面右側是當前搜索結果(TopN)中雜志來源和文獻作者(頻率比較高)例如,雜志列表,是把當前搜索結果中的文獻進行期刊歸類并按照期刊文獻數從高到低進行排列,點擊可以直接查看對應期刊的具體文獻詳情。哪家公司是做文獻知識服務的?福建文獻知識發現大概價格多少文獻的概念:“文獻”一詞開始早見于《論語·八佾》:“夏禮吾能言之,杞不足徵也;...
-
 運營文獻知識發現發現
運營文獻知識發現發現文獻數據庫列表明細:當前數據源檢索下的站點明細(如:數據源為一個數據庫,則在站點明細中只出現該數據可。) 在站點明細中可以,可以查看各個具體文獻數據庫的瀏覽,閱讀,下載,以及流量情況,支持對應排序。用戶列表明細,可以查看用戶具體的訪問情況,例如:當前選擇的數據源為CNKI這個數據庫。則在用戶列表中為所有用戶訪問CNKI的明細,包含,閱讀,下載,瀏覽,站點數以及流量。如選擇統計數據源為部門,則用戶站點數就為該用戶一共訪問的數據庫個數。 ?依據實時搜索結果Top N篇文獻的篇名和摘要進行文本深度解析,分別生成的中、英文聯想關聯矩陣,即語義腦圖。運營文獻知識發現發現報刊閱覽期刊又稱“雜...
-
 網絡文獻知識發現服務費
網絡文獻知識發現服務費文獻傳遞是將用戶所需的文獻復制品以有效的方式和合理的費用,直接或間接傳遞給用戶的一種非返還式的文獻提供服務,它具有快速、高效、簡便的特點。為滿足用戶對圖書館缺藏期刊論文、圖書等文獻的需求,更好地為教學科研服務,部分圖書館會為用戶提供文獻傳遞服務。文獻類型包括期刊論文、學位論文、會議論文、科技報告、專項權利文獻等。現代意義的文獻傳遞是在信息技術的支撐下從館際互借發展而來,但又優于館際互借的一種服務。如果師生讀者在學校圖書館現有的資源( 紙質資源和電子資源 ) 中找不到所需要的原文文獻(主要為論文),您就可以到圖書館申請開展文獻傳遞服務。通過開展文獻傳遞服務,不僅緩解了圖書館經費、資源不足與讀者日...
-
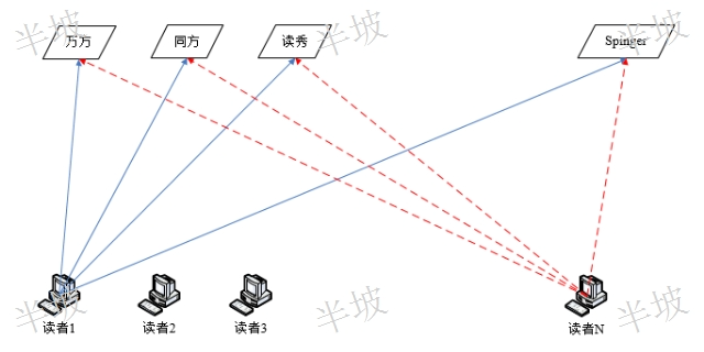 運營文獻知識發現平臺
運營文獻知識發現平臺左側的語義腦圖中任意節點可以在右側文獻詳情界面顯示其相關文獻。右側相關文獻界面則進一步揭示了當前文獻中所有的概念語詞(紅色下劃線)。選擇其中的任意詞(鼠標定位),可以查看該概念詞所有的相關文獻,并且以該概念詞為中心節點,可以在左側語義腦圖子窗口,重構一幅全新的語義腦圖(發明專項權利)。紅色下劃線標注了一篇文獻中的所有細分概念《嵌入式知識鏈分析》無縫嵌入原始文獻數據庫,將傳統文獻搜索引擎一維的文獻顯示模式提升為二維的概念語詞級別的關聯矩陣顯示模式。其基于實時搜索結果的知識層面的語義概念專指、聚類、收斂、發散、顯性、隱性及其多維度的關聯揭示等功能特色,在尤為強調知識發現、知識創新的當日,將...
-
河南參考文獻知識發現
文本語義腦圖(Text Mind Map)為輔助讀者研判一篇文獻的相關性,檢索系統通常會針對某一文獻內容特征進行單一維度的文獻聚類細分。例如:依據關鍵詞或者依據作者對檢出文獻進行再聚類并揭示其所對應的相關文獻。 文本語義腦圖突破傳統搜索引擎查詢結果單維列表呈現的局限性,以讀者搜索詞為起點,形成一個m行乘n列的文本語義概念的關聯矩陣表達。其目的是輔助讀者發現搜索結果內的文本概念之間的隱性知識關聯以及拓展讀者啟發式發散思維。文獻知識的研究范圍主要是研究文獻的分類與編目、文獻形成發展歷史、各種文獻的特點與用途、文獻的檢索等。河南參考文獻知識發現系統支持的文獻數據庫《致匯?一站式學術搜索》可以一次性...
-
天津文獻知識發現多少錢
二次文獻(secondarydocument):是指文獻工作者對一次文獻進行加工、提煉和壓縮之后所得到的產物,是為了便于管理和利用一次文獻而編輯、出版和累積起來的工具性文獻。檢索工具書和網上檢索引擎是典型的二次文獻。三次文獻(tertiarydocument):是指對有關的一次文獻和二次文獻進行入的分析研究綜合概括而成的產物。如大百科全書、辭典、電子百科等。檢索狹義的檢索(Retrieval)是指依據一定的方法,從已經組織好的大量有關文獻中,查找并獲取特定的相關文獻的過程。這里的文獻,不是通常所指的文獻本身,而是關于文獻的信息或文獻的線索。廣義的檢索包括信息的存儲和檢索兩個過程(Storage...
-
文獻知識發現案例
系統支持的文獻數據庫:理論上支持所有的HTML4和HTML5類別文獻服務數據庫。比如知網、萬方、以及大多數的外文文獻資源。系統支持圖書館所購買的網上文獻服務數據庫;支持本地鏡像文獻數據庫;支持Web模式的圖書館自建數據庫;也支持本館圖書館自動化管理系統中的Web書目查詢。系統可以同時融入網上開放式的公共學術類搜索引擎,例如GoogleScholar、百度學術、Being學術、醫學專業領域內的PubMed等。對于圖書館沒有購買的收費數據庫,系統同樣支持對方公開開放的部分(比如搜索和瀏覽),未授權部分(原文下載)則不支持(系統提供館員館際原文傳遞服務模塊支持)。簡而言之,系統支持訪問可達并...
-
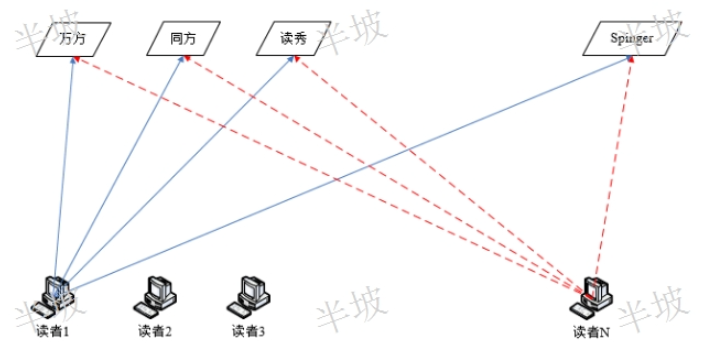 數字圖書館文獻知識發現聯系方式
數字圖書館文獻知識發現聯系方式相關文獻與語義腦圖互為關聯揭示:左側的語義腦圖中任意節點可以在右側文獻詳情界面顯示其相關文獻。右側相關文獻界面則進一步揭示了當前文獻中所有的概念語詞(紅色下劃線)。選擇其中的任意詞(鼠標定位),可以查看該概念詞所有的相關文獻,并且以該概念詞為重心節點,可以在左側語義腦圖子窗口,重構一幅全新的語義腦圖(發明專項權利)。《嵌入式知識鏈分析》無縫嵌入原始文獻數據庫,將傳統文獻搜索引擎一維的文獻顯示模式提升為二維的概念語詞級別的關聯矩陣顯示模式。其基于實時搜索結果的知識層面的語義概念專指、聚類、收斂、發散、顯性、隱性及其多維度的關聯揭示等功能特色,在尤為強調知識發現、知識創新的未來,將會為讀者...
-
河南文獻知識發現聯系方式
文獻作為一種語言和知識系統,字、詞、句之間皆可構成特定的復雜網絡關系。知識超越簡單的時空排序、內容關聯和頁碼順序,通過關鍵詞、類別、主題、命名實體、函數、圖表等實現跨文本甚至跨媒介關聯,通過界面或網絡聯結呈現。知識網絡讓研究者能直觀發現在詞頻統計之外的知識內部的更深層關系,如整體網絡特征、**人物功能與不同時期人物關系的演化模式。共被引分析通過引文之間的共現,可實現基于知識的聚合,解釋知識的主題結構和新穎度。在大數據知識關聯中,人們更關注的是知識信息的網絡結構與流動轉化。隨著更多要素和變量納入,知識會呈現不同的形態、性能與趨勢。在更為宏闊的視域下,知識獲取已非直接來自單個文本,亦非來自文本本身...
-
創新文獻知識發現銷售電話
文獻屬性是文獻本身所固有的性質,可概括為四個方面:知識信息性、物質實體性、人工記錄性、動態發展性,文獻特征包括文獻外表特征和文獻內容特征兩方面。它指文獻載體直接可見的特殊表征,如文獻的題名、責任者、序號、引證文獻題名以及文獻的類型、文種、出版事項、篇幅、開本、字體、出處等。它是識別文獻的直接依據,某些外表特征具有檢索意義,是檢索工具著錄的對象。文獻外表特征是直觀的、顯面易見的,它影響著文獻內容特征,也影響著文獻的存儲、利用和傳遞文獻內容特征。它指文獻內容所含信息和知識的特殊表征,如文獻所屬的學科門類、論述的主題對象、表達的基本觀點和涉及的時間與空間范圍等。它是判斷文獻價值的根本依據。文獻知識到...
-
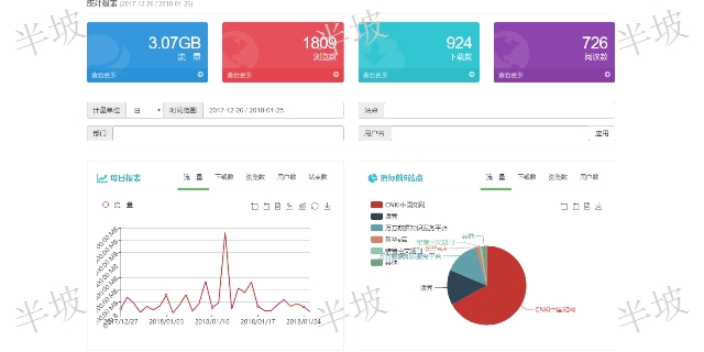 參考文獻知識發現服務
參考文獻知識發現服務作者是誰?他們還出版了什么?這篇論文是他們曾經研究內容的工作延伸嗎?文章的目的是什么?你認可他的觀點嗎?他的這篇文章研究調查、評論或分析了什么?這個課題有意義嗎?為什么?作者采用了哪些方法、理論或分析框架?這些是適當或合理的嗎?得出了哪些結論?這些證據是否合理?研究設計有什么限制嗎?調查教過是否確鑿適用于你的研究?上述的這些問題可以幫助你更好的對文獻進行分析或闡述,不過,它只是一個起點,你可以試著在閱讀時提出并添加自己的問題或想法。當你開始試圖評估文章、研究和方法時,了解誰是你研究領域中的會對你很有幫助。你可以通過搜索,找到哪些文章或作者被引用的頻繁,這被稱為「citationsearc...
-
 廣東品牌文獻知識發現
廣東品牌文獻知識發現文獻的類型:文獻可以按照不同的劃分標準對其進行分類,如文獻載體類型、文獻級別等,但其基本類型是根據文獻的出版形式來劃分的。文獻根據其出版形式有圖書,圖書又稱為書籍,是內容比較成熟、資料比較系統、有完整定型的裝幀形式的出版物。按其篇幅和出版形式的不同,可分為小冊子、單卷書、多卷書、叢書等。公開出版發行的圖書,一般標注有國際標準書號(ISBN)。文獻根據其出版形式有期刊,期刊是指采用統一名稱,定期或不定期出版的匯集許多個著者論文的連續出版物。期刊與圖書相比,它具有出版周期短、報導速度快、內容新穎、學科廣、數量大、種類多等特點,是人們進行科學研究、交流學術思想經常利用的文獻信息資源。公開出版發行的期...
-
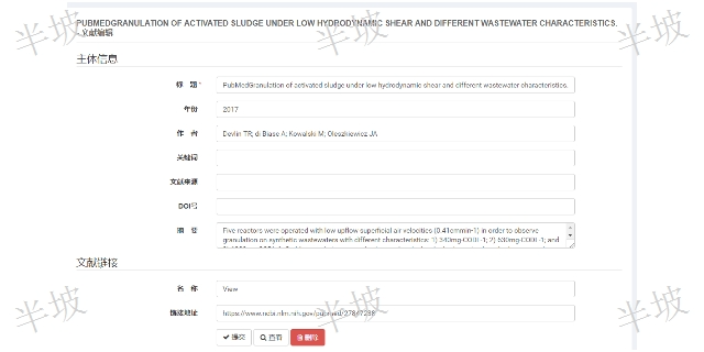 創新文獻知識發現有什么用
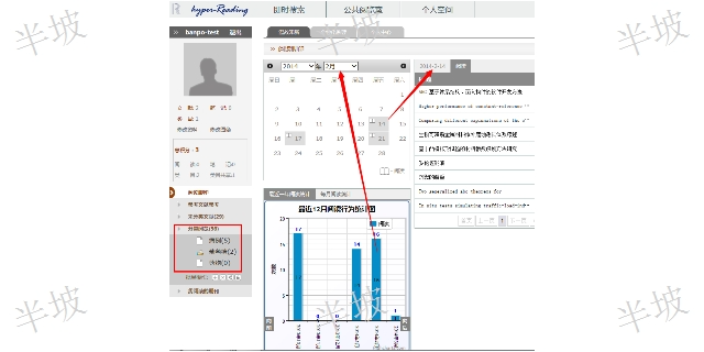
創新文獻知識發現有什么用文獻閱讀分析及其指引:語義腦圖的讀者服務界面是:左側部分顯示語義腦圖。右側部分顯示語義概念所對應的文獻內容。 在文獻內容顯示部分,當鼠標移動到某一篇具體文獻時,系統會以紅色底線加亮顯示當前文獻中可能的語義概念。 繼續移動鼠標到某一個具體語義概念,本示例中的“etilolgy”,彈出框可以顯示該概念術語在Top-N文獻中的文獻數。點擊彈出框中的“新的語義腦圖”,系統會在界面左側窗口,重新繪制一幅以“etilolgy”為起點的新的語義腦圖。文獻為我們提供了什么樣的幫助?創新文獻知識發現有什么用 左側的語義腦圖中任意節點可以在右側文獻詳情界面顯示其相關文獻。右側相關文獻界面則進一步揭示了當...
-
上海文獻知識發現多少錢
文獻特征矩陣:為輔助讀者研判一篇文獻的相關性,檢索系統通常會針對某一文獻內容特征進行單一維度的文獻聚類細分。例如:依據關鍵詞或者依據作者,對檢出文獻進行再聚類并揭示其所對應的相關文獻。對于讀者而言,有時,用戶可能更加關心的是多個文獻內容特征之間的相互關聯,例如想了解某位作者可能所涉及的相關主題;想了解某個主題可能涉及的作者或其他文本自由詞熱點等等。由此,上海半坡的文獻特征矩陣技術,依據實時一站式讀者文獻搜索結果的TopN篇,將諸如PubMed人工標引的主要主題詞(MajorMeSH)、次要主題(MinorMeSH)、作者關鍵詞、作者、篇名自由詞等5列(字段),在同一個顯示矩陣里以多維度...
-
圖書館文獻知識發現價格多少
《一站式學術搜索》依據讀者搜索指令,從參與一站式搜索的文獻數據庫中實時獲取搜索結果(每個文獻數據庫的一次性返回結果數可以由系統管理員自定義)。搜索結果界面:l界面上部的搜索結果文獻按年度劃分的時間軸線圖時間軸線反映各個文獻數據庫搜索結果合并(已去重)后該年度的文獻數。選中任意文獻數,則在界面中間的主體部分將顯示該年度的文獻。界面左側反映當前參與搜索的文獻數據庫及其結果文獻數點擊任意文獻數據庫,則界面中間的主體部分顯示該文獻數據庫當前所返回的文獻(原始文獻數據庫的搜索結果順序)。界面中間的文獻內容顯示主體部分文獻顯示內容包含文獻標題、作者、摘要、文獻出處、期刊權重、原文獻鏈接及其引用鏈接...
-
怎樣文獻知識發現包括什么
《一站式學術搜索》界面:一站式搜索界面示例界面上部的搜索結果文獻按年度劃分的時間軸線圖時間軸線反映各個文獻數據庫搜索結果合并(已去重)后該年度的文獻數。選中任意文獻數,則在界面中間的主體部分將顯示該年度的文獻。界面左側反映當前參與搜索的文獻數據庫及其結果文獻數點擊任意文獻數據庫,則界面中間的主體部分顯示該文獻數據庫當前所返回的文獻(原始文獻數據庫的搜索結果順序)。界面中間的文獻內容顯示主體部分文獻顯示內容包含文獻標題、作者、摘要、文獻出處、期刊權重、原文獻鏈接及其引用鏈接。期刊權重:圖書館館員可以后臺通過Excel格式導入至多5種本館需求的期刊評價指標體系(如IF、SJR、SNIP、C...
-
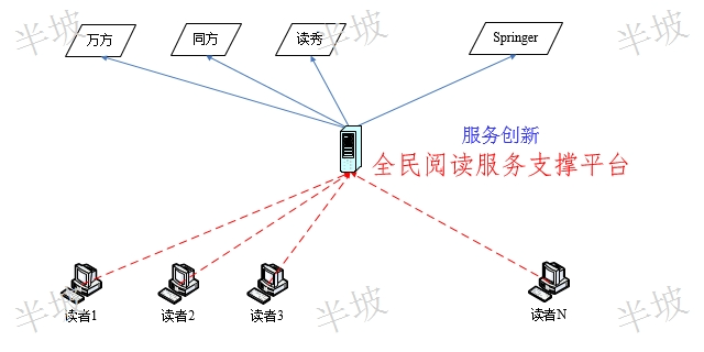 上海文獻知識發現采購
上海文獻知識發現采購文獻數據庫列表明細:當前數據源檢索下的站點明細(如:數據源為一個數據庫,則在站點明細中只出現該數據可。) 在站點明細中可以,可以查看各個具體文獻數據庫的瀏覽,閱讀,下載,以及流量情況,支持對應排序。用戶列表明細,可以查看用戶具體的訪問情況,例如:當前選擇的數據源為CNKI這個數據庫。則在用戶列表中為所有用戶訪問CNKI的明細,包含,閱讀,下載,瀏覽,站點數以及流量。如選擇統計數據源為部門,則用戶站點數就為該用戶一共訪問的數據庫個數。 ?上海半坡的數字圖書館為授權讀者提供遠程文獻閱讀和移動閱讀服務。上海文獻知識發現采購文獻利用:高校圖書館收藏大量的各學科、各文種、各種載體形式的文獻...
-
江西品牌文獻知識發現
二次文獻(secondarydocument):是指文獻工作者對一次文獻進行加工、提煉和壓縮之后所得到的產物,是為了便于管理和利用一次文獻而編輯、出版和累積起來的工具性文獻。檢索工具書和網上檢索引擎是典型的二次文獻。三次文獻(tertiarydocument):是指對有關的一次文獻和二次文獻進行入的分析研究綜合概括而成的產物。如大百科全書、辭典、電子百科等。檢索狹義的檢索(Retrieval)是指依據一定的方法,從已經組織好的大量有關文獻中,查找并獲取特定的相關文獻的過程。這里的文獻,不是通常所指的文獻本身,而是關于文獻的信息或文獻的線索。廣義的檢索包括信息的存儲和檢索兩個過程(Storage...
-
信息化文獻知識發現預算
文獻是記錄有知識或信息的一切載體。文獻是各類圖書、期刊等各種出版物的總和。文獻是記錄、積累、傳播和繼承知識的***的手段,是人類在社會活動中獲取情報的**基本、**主要的來源,也是交流傳播情報的**基本手段。其中包括知識信息內容,這是文獻的靈魂所在、信息符號,即揭示和表達知識信息的標識符號,如文字、圖形、數字代碼、聲頻、視頻等。載體材料,如龜甲獸骨、竹木縑帛、金石泥陶、紙張、膠片膠卷、磁帶磁盤、光盤、穿孔紙帶等。上海半坡是專門為圖書館提供文獻知識服務的公司.信息化文獻知識發現預算 嵌入式知識鏈分析:讀者文獻搜索時,系統實時感知、分析當前搜索結果的TopN篇文獻,并在原始搜索結果界面...
-
互聯網文獻知識發現口碑推薦
文獻數據庫列表明細:當前數據源檢索下的站點明細(如:數據源為一個數據庫,則在站點明細中只出現該數據可。) 在站點明細中可以,可以查看各個具體文獻數據庫的瀏覽,閱讀,下載,以及流量情況,支持對應排序。用戶列表明細,可以查看用戶具體的訪問情況,例如:當前選擇的數據源為CNKI這個數據庫。則在用戶列表中為所有用戶訪問CNKI的明細,包含,閱讀,下載,瀏覽,站點數以及流量。如選擇統計數據源為部門,則用戶站點數就為該用戶一共訪問的數據庫個數。 ?文獻知識怎么準確檢索想要查詢的內容?互聯網文獻知識發現口碑推薦 隱性知識鏈發現:語義腦圖中,給定重心節點(搜索詞)A,任意興趣節點C(黑色背...
-
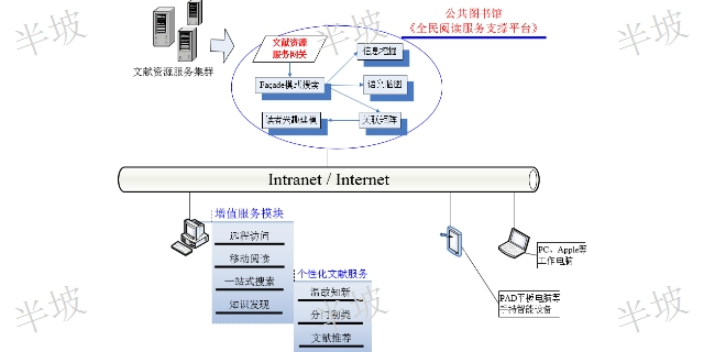 北京文獻知識發現排行榜
北京文獻知識發現排行榜文獻是記錄有知識或信息的一切載體。文獻是各類圖書、期刊等各種出版物的總和。文獻是記錄、積累、傳播和繼承知識的***的手段,是人類在社會活動中獲取情報的**基本、**主要的來源,也是交流傳播情報的**基本手段。其中包括知識信息內容,這是文獻的靈魂所在、信息符號,即揭示和表達知識信息的標識符號,如文字、圖形、數字代碼、聲頻、視頻等。載體材料,如龜甲獸骨、竹木縑帛、金石泥陶、紙張、膠片膠卷、磁帶磁盤、光盤、穿孔紙帶等。上海半坡提供跨越多個異構文獻知識數據庫Fa?ade模式的一站式搜索服務。北京文獻知識發現排行榜 《一站式學術搜索》是上海半坡網絡技術有限公司致匯?《數字圖書館增值服務平臺...