-
供應中山市廣東歐曼教育裝備護眼燈源頭工廠價格中山市歐曼教育裝備供應
-
供應中山市健康教室護眼燈供應商批發中山市歐曼教育裝備供應
-
銷售中山市廣東歐曼教育裝備護眼燈源頭工廠多少錢中山市歐曼教育裝備供應
-
提供中山市廣東歐曼教育裝備護眼燈源頭工廠廠家中山市歐曼教育裝備供應
-
銷售中山市廣東歐曼教育裝備護眼燈源頭工廠多少錢中山市歐曼教育裝備供應
-
銷售中山市健康教室護眼燈供應商批發中山市歐曼教育裝備供應
-
提供中山市健康教室護眼燈供應商批發中山市歐曼教育裝備供應
-
供應中山市健康教室護眼燈供應商直銷中山市歐曼教育裝備供應
-
銷售中山市健康智慧無塵黑板椅供應商報價中山市歐曼教育裝備供應
-
銷售中山市健康智慧無塵黑板椅供應商報價中山市歐曼教育裝備供應
溧水區參考數據處理熱線
在數據可視化部分,需要對數據的計算結果進行分析和展現,有BIEE,Microstrategy,Yonghong的Z-Suite等工具。數據處理的軟件有EXCEL MATLAB Origin等等,當前流行的圖形可視化和數據分析軟件有Matlab,Mathmatica和Maple等。這些軟件功能強大,可滿足科技工作中的許多需要,但使用這些軟件需要一定的計算機編程知識和矩陣知識,并熟悉其中大量的函數和命令。而使用Origin就像使用Excel和Word那樣簡單,只需點擊鼠標,選擇菜單命令就可以完成大部分工作,獲得滿意的結果。大數據時代,需要可以解決大量數據、異構數據等多種問題帶來的數據處理難題,Hadoop是一個分布式系統基礎架構,由Apache基金會開發。用戶可以在不了解分布式底層細節的情況下,開發分布式程序。充分利用集群的威力高速運算和存儲。Hadoop實現了一個分布式文件系統 Hadoop Distributed File System,HDFS。HDFS有著高容錯性的特點,并且設計用來部署在低廉的硬件上。而且它提供高傳輸率來訪問應用程序的數據,適合那些有著超大數據集的應用程序。用戶可以在不了解分布式底層細節的情況下,開發分布式程序。充分利用集群的威力高速運算和存儲。溧水區參考數據處理熱線
②根據數據處理時間的分配方式區分,有批處理方式、分時處理方式和實時處理方式。③根據數據處理空間的分布方式區分,有集中式處理方式和分布處理方式。④根據計算機**處理器的工作方式區分,有單道作業處理方式、多道作業處理方式和交互式處理方式。數據處理對數據(包括數值的和非數值的)進行分析和加工的技術過程。包括對各種原始數據的分析、整理、計算、編輯等的加工和處理。比數據分析含義廣。隨著計算機的日益普及,在計算機應用領域中,數值計算所占比重很小,通過計算機數據處理進行信息管理已成為主要的應用。鼓樓區參考數據處理哪個好數據計算:進行各種算術和邏輯運算,以便得到進一步的信息。

導入/預處理雖然采集端本身會有很多數據庫,但是如果要對這些大量數據進行有效的分析,還是應該將這些來自前端的數據導入到一個集中的大型分布式數據庫,或者分布式存儲集群,并且可以在導入基礎上做一些簡單的清洗和預處理工作。也有一些用戶會在導入時使用來自Twitter的Storm來對數據進行流式計算,來滿足部分業務的實時計算需求。導入與預處理過程的特點和挑戰主要是導入的數據量大,每秒鐘的導入量經常會達到百兆,甚至千兆級別。
采集在大數據的采集過程中,其主要特點和挑戰是并發數高,因為同時有可能會有成千上萬的用戶來進行訪問和操作,比如火車票售票網站和淘寶,它們并發的訪問量在峰值時達到上百萬,所以需要在采集端部署大量數據庫才能支撐。并且如何在這些數據庫之間進行負載均衡和分片的確是需要深入的思考和設計。統計/分析統計與分析主要利用分布式數據庫,或者分布式計算集群來對存儲于其內的大量數據進行普通的分析和分類匯總等,以滿足大多數常見的分析需求,在這方面,一些實時性需求會用到EMC的GreenPlum、Oracle的Exadata,以及基于MySQL的列式存儲Infobright等,而一些批處理,或者基于半結構化數據的需求可以使用Hadoop。統計與分析這部分的主要特點和挑戰是分析涉及的數據量大,其對系統資源,特別是I/O會有極大的占用。而數據庫技術就是針對該需求目標進行研究并發展和完善起來的計算機應用的一個分支。
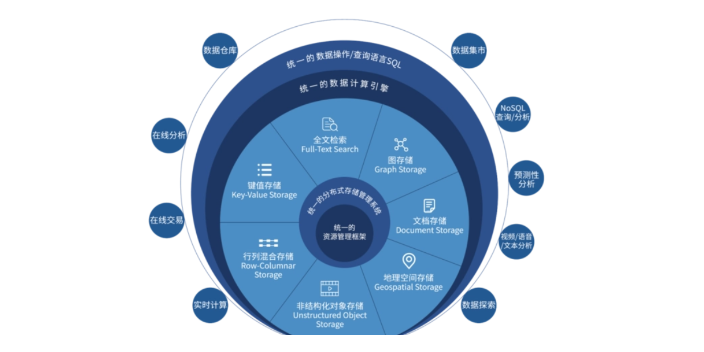
商務網站有關商務網站的數據處理:由于網站的訪問量非常大,在進行一些專業的數據分析時,往往要有針對性的數據清洗,即把無關的數據、不重要的數據等處理掉。接著對數據進行相關分分類,進行分類劃分之后,就可以根據具體的分析需求選擇模式分析的技術,如路徑分析、興趣關聯規則、聚類等。通過模式分析,找到有用的信息,再通過聯機分析(OLAP)的驗證,結合客戶登記信息,找出有價值的市場信息,或發現潛在的市場 [1] 。數據處理是從大量的原始數據抽取出有價值的信息,即數據轉換成信息的過程。主要對所輸入的各種形式的數據進行加工整理,其過程包含對數據的收集、存儲、加工、分類、歸并、計算、排序、轉換、檢索和傳播的演變與推導全過程。數據處理是從大量的原始數據抽取出有價值的信息,即數據轉換成信息的過程。鼓樓區參考數據處理哪個好
大數據處理數據時代理念的三大轉變:要全體不要抽樣,要效率不要***精確,要相關不要因果。溧水區參考數據處理熱線
挖掘與前面統計和分析過程不同的是,數據挖掘一般沒有什么預先設定好的主題,主要是在現有數據上面進行基于各種算法的計算,從而起到預測的效果,從而實現一些高級別數據分析的需求。比較典型算法有用于聚類的K-Means、用于統計學習的SVM和用于分類的NaiveBayes,主要使用的工具有Hadoop的Mahout等。該過程的特點和挑戰主要是用于挖掘的算法很復雜,并且計算涉及的數據量和計算量都很大,還有,常用數據挖掘算法都以單線程為主 [2] 。溧水區參考數據處理熱線
南京紅袋鼠大數據科技有限公司匯集了大量的優秀人才,集企業奇思,創經濟奇跡,一群有夢想有朝氣的團隊不斷在前進的道路上開創新天地,繪畫新藍圖,在江蘇省等地區的商務服務中始終保持良好的信譽,信奉著“爭取每一個客戶不容易,失去每一個用戶很簡單”的理念,市場是企業的方向,質量是企業的生命,在公司有效方針的領導下,全體上下,團結一致,共同進退,**協力把各方面工作做得更好,努力開創工作的新局面,公司的新高度,未來南京紅袋鼠大數據科技供應和您一起奔向更美好的未來,即使現在有一點小小的成績,也不足以驕傲,過去的種種都已成為昨日我們只有總結經驗,才能繼續上路,讓我們一起點燃新的希望,放飛新的夢想!
- 江蘇方便數據處理介紹 2025-04-06
- 秦淮區數據處理哪個好 2025-04-06
- 江寧區大數據技術包含 2025-04-06
- 浦口區什么是大數據技術平臺 2025-04-06
- 溧水區如何數據處理包含 2025-04-06
- 溧水區方便數據處理信息中心 2025-04-06
- 棲霞區品牌大數據技術介紹 2025-04-06
- 秦淮區貿易數據處理大概是 2025-04-06
- 棲霞區互聯網大數據技術包含 2025-04-06
- 六合區如何大數據技術信息中心 2025-04-06
- 寶安區方便物業24小時服務 2025-04-06
- 揚州綜合工程承包選擇 2025-04-06
- 南通PMMA燈罩怎么樣 2025-04-06
- 安徽中小企業使用T云國內版有助于提高營銷效率 2025-04-06
- AQP驗廠HIGG驗證SEDEX認證Target驗廠sedex驗廠SEDEX驗廠SLCP驗廠 2025-04-06
- 唐山哪里的移動應用程序靠譜 2025-04-06
- 舟山醫院勞務外包外包 2025-04-06
- 西城區運營廣告設計進口 2025-04-06
- 河南電商包裝設計 2025-04-06
- 江蘇網絡營銷技術服務公司 2025-04-06